Copyright (C) 1997 Peter Miller. All rights reserved.
This paper is also available in PostScript format.
For large UNIX projects, the traditional method of building the project is to use recursive make. On some projects, this results in build times which are unacceptably large, when all you want to do is change one file. In examining the source of the overly long build times, it became evident that a number of apparently unrelated problems combine to produce the delay, but on analysis all have the same root cause.This paper explores an number of problems regarding the use of recursive make, and shows that they are all symptoms of the same problem. Symptoms that the UNIX community have long accepted as a fact of life, but which need not be endured any longer. These problems include recursive makes which take ``forever'' to work out that they need to do nothing, recursive makes which do too much, or too little, recursive makes which are overly sensitive to changes in the source code and require constant Makefile intervention to keep them working.
The resolution of these problems can be found by looking at what make does, from first principles, and then analyzing the effects of introducing recursive make to this activity. The analysis shows that the problem stems from the artificial partitioning of the build into separate subsets. This, in turn, leads to the symptoms described. To avoid the symptoms, it is only necessary to avoid the separation; to use a single Makefile for the whole project.
This conclusion runs counter to much accumulated folk wisdom in building large projects on UNIX. Some of the main objections raised by this folk wisdom are examined and shown to be unfounded. The results of actual use are far more encouraging, with routine development performance improvements significantly faster than intuition may indicate. The use of a single project Makefile is not as difficult to put into practice as it may first appear.
This paper explores some significant problems encountered when developing software projects using the recursive make technique. A simple solution is offered, and some of the implications of that solution are explored.
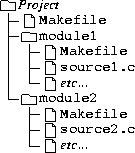
Recursive make results in a directory tree which looks something like this:
This paper assumes that you have installed GNU Make on your system and are moderately familiar with its features. Some features of make described below may not be available if you are using the limited version supplied by your vendor.
Make determines how to build the target by constructing a directed acyclic graph, the DAG familiar to many Computer Science students. The vertices of this graph are the files in the system, the edges of this graph are the inter-file dependencies. The edges of the graph are directed because the pair-wise dependencies are ordered; resulting in a acyclic graph - things which look like loops are resolved by the direction of the edges.
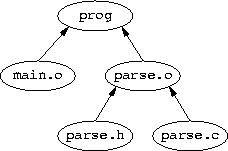
This paper will use a small example project for its analysis. While the number of files in this example is small, there is sufficient complexity to demonstrate all of the above recursive make problems. First, however, the project is presented in a non-recursive form.

OBJ = main.o parse.o prog: $(OBJ) $(CC) -o $@ $(OBJ) main.o: main.c parse.h $(CC) -c main.c parse.o: parse.c parse.h $(CC) -c parse.c |
The above Makefile can be drawn as a DAG in the following form:
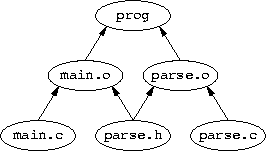
This is an acyclic graph is because of the arrows which express the ordering of the relationship between the files. If there was a circular dependency according to the arrows, it would be an error.
Note that the object files (.o) are dependent on the include files (.h) even though it is the source files (.c) which do the including. This is because if an include file changes, it is the object files which are out-of-date, not the source files.
The second part of what make does it to perform a postorder traversal of the DAG. That is, the dependencies are visited first. The actual order of traversal is undefined, but most make implementations work down the graph from left to right for edges below the same vertex, and most projects implicitly rely on this behavior. The last-time-modified of each file is examined, and higher files are determined to be out-of-date if any of the lower files on which they depend are younger. Where a file is determined to be out-of-date, the action associated with the relevant graph edge is performed (in the above example, a compile or a link).
The use of recursive make affects both phases of the operation of make: it causes make to construct an inaccurate DAG, and it forces make to traverse the DAG in an inappropriate order.
The directory structure is as follows:
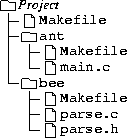
MODULES = ant bee
all:
for dir in $(MODULES); do \
(cd $$dir; ${MAKE} all); \
done
|
all: main.o main.o: main.c ../bee/parse.h $(CC) -I../bee -c main.c |
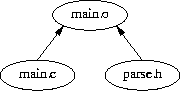
OBJ = ../ant/main.o parse.o all: prog prog: (OBJ) $(CC) -o $@ $(OBJ) parse.o: parse.c parse.h $(CC) -c parse.c |
Take a close look at the DAGs. Notice how neither is complete - there are vertices and edges (files and dependencies) missing from both DAGs. When the entire build is done from the top level, everything will work.
But what happens when small changes occur? For example, what would happen of the parse.c and parse.h files were generated from a parse.y yacc grammar? This would add the following lines to the bee/Makefile:
parse.c parse.h: parse.y $(YACC) -d parse.y mv y.tab.c parse.c mv y.tab.h parse.h |
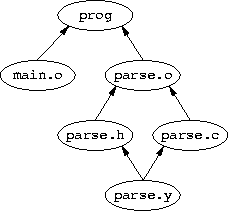
This change has a simple effect: if parse.y is edited, main.o will not be constructed correctly. The is because the DAG for ant knows about only some of the dependencies of main.o, and the DAG for bee knows none of them.
To understand why this happens, it is necessary to look at the actions make will take from the top level. Assume that the project is in a self-consistent state. Now edit parse.y in such a way that the generated parse.h file will have non-trivial differences. However, when the top-level make is invoked, first ant and then bee is visited. But ant/main.o is not recompiled, because bee/parse.h has not yet been regenerated and thus does not yet indicate that main.o is out-of-date. It is not until bee is visited by the recursive make that parse.c and parse.h are reconstructed, followed by parse.o. When the program is linked main.o and parse.o are non-trivially incompatible. That is, the program is wrong.
To answer this question, it is necessary to look, not at the graphs, but the order of traversal of the graphs. In order to operate correctly, make needs to perform a postorder traversal, but in separating the DAG into two pieces, make has not been allowed to traverse the graph in the necessary order - instead the project has dictated an order of traversal. An order which, when you consider the original graph, is plain wrong. Tweaking the top-level Makefile corrects the order to one similar to that which make could have used. Until the next dependency is added...
MODULES = ant bee
all:
for dir in $(MODULES); do \
(cd $$dir; ${MAKE} all); \
done
for dir in $(MODULES); do \
(cd $$dir; ${MAKE} all); \
done
|
This doubles then length of time it takes to perform the build. But that is not all: there is no guarantee that two passes are enough! The upper bound of the number of passes is not even proportional to the number of modules, it is instead proportional to the number of graph edges which cross module boundaries.
.PHONY: ../bee/parse.h
../bee/parse.h:
cd ../bee; \
make clean; \
make all
|
Did make get it wrong? No. This is a case of the ancient GIGO principle: Garbage In, Garbage Out. Incomplete Makefiles are wrong Makefiles.
To avoid these problems, don't break the DAG into pieces; instead, use one Makefile for the entire project. It is not the recursion itself which is harmful, it is the crippled Makefiles which are used in the recursion which are wrong. It is not a deficiency of make itself that recursive make is broken, it does the best it can with the flawed input it is given.
``But, but, but... You can't do that!'' I hear you cry. ``A single Makefile is too big, it's unmaintainable, it's too hard to write the rules, you'll run out of memory, I only want to build my little bit, the build take too long. It's just not practical.''These are valid concerns, and they frequently lead make users to the conclusion that re-working their build process does not have any short- or long-term benefits. This conclusion is based on ancient, enduring, false assumptions.
Recursive Makefiles have a great deal of repetition. Many projects solve this by using include files. By using a single Makefile for the project, the need for the ``common'' include files disappears - the single Makefile is the common part.
GCC allows a -o option in conjunction with the -c option, and GNU Make knows this. This results in the implicit compilation rule placing the output in the correct place. Older and dumber C compilers, however, may not allow the -o option with the -c option, and will leave the object file in the top-level directory (i.e. the wrong directory). There are three ways for you to fix this: get GNU Make and GCC, override the built-in rule with one which does the right thing, or complain to your vendor.
Also, K&R C compilers will start the double-quote include path (#include "filename.h") from the current directory. This will not do what you want. ANSI C compliant C compilers, however, start the double-quote include path from the directory in which the source file appears; thus, no source changes are required. If you don't have an ANSI C compliant C compiler, you should consider installing GCC on your system as soon as possible.
Developers always have the option of giving make a specific target. This is always the case, it's just that we usually rely on the default target in the Makefile in the current directory to shorten the command line for us. Building ``my little bit'' can still be done with a whole project Makefile, simply by using a specific target, and an alias if the command line is too long.
Is doing a full project build every time so absurd? If a change made in a module has repercussions in other modules, because there is a dependency the developer is unaware of (but the Makefile is aware of), isn't it better that the developer find out as early as possible? Dependencies like this will be found, because the DAG is more complete than in the recursive case.
The developer is rarely a seasoned old salt who knows every one of the million lines of code in the product. More likely the developer is a short-term contractor or a junior. You don't want implications like these to blow up after the changes are integrated with the master source, you want them to blow up on the developer in some nice safe sand-box far away from the master source.
If you want to make ``just your little'' bit because you are concerned that performing a full project build will corrupt the project master source, due to the directory structure used in your project, see the ``Projects versus Sand-Boxes'' section below.
In order to build the DAG, make must ``stat'' 3000 files, plus an additional 2000 files or so, depending on which implicit rules your make knows about and your Makefile has left enabled. On the author's humble 66MHz i486 this takes about 10 seconds; on native disk on faster platforms it goes even faster. With NFS over 10MB Ethernet it takes about 10 seconds, no matter what the platform.
This is an astonishing statistic! Imagine being able to a single file compile, out of 1000 source files, in only 10 seconds, plus the time for the compilation itself.
Breaking the set of files up into 100 modules, and running it as a recursive make takes about 25 seconds. The repeated process creation for the subordinate make invocations take quite a long time.
Hang on a minute! On real-world projects with less than 1000 files, it takes an awful lot longer than 25 seconds for make to work out that it has nothing to do. For some projects, doing it in only 25 minutes would be an improvement! The above result tells us that it is not the number of files which is slowing us down (that only takes 10 seconds), and it is not the repeated process creation for the subordinate make invocations (that only takes another 15 seconds). So just what is taking so long?
The traditional solutions to the problems introduced by recursive make often increase the number of subordinate make invocations beyond the minimum described here; e.g. to perform multiple repetitions (3.3.2), or to overkill cross-module dependencies (3.3.3). These can take a long time, particularly when combined, but do not account for some of the more spectacular build times; what else is taking so long?
Complexity of the Makefile is what is taking so long. This is covered, below, in the Efficient Makefiles section.
By consistently using C include files which contain accurate interface definitions (including function prototypes), this will produce compilation errors in many of the cases which would result in a defective product. By doing whole-project builds, developers discover such errors very early in the development process, and can fix the problems when they are least expensive.
On such a computer, the above project with its 3000 files detailed in the whole-project Makefile, would probably not allow the DAG and rule actions to fit in memory.
But we are not using PDP11s any more. The physical memory of modern computers exceeds 10MB for small computers, and virtual memory often exceeds 100MB. It is going to take a project with hundreds of thousands of source files to exhaust virtual memory on a small modern computer. As the 1000 source file example takes less than 100KB of memory (try it, I did) it is unlikely that any project manageable in a single directory tree on a single disk will exhaust your computer's memory.
By making sure that each Makefile is complete, you arrive at the point where the Makefile for at least one module contains the equivalent of a whole-project Makefile (recall that these modules form a single project and are thus inter-connected), and there is no need for the recursion any more.
Builds can take ``forever'' for both these reasons: the traditional fixes for the separated DAG may be building too much and your Makefile may be inefficient.
The input language for Makefiles is deceptively simple. A crucial distinction that often escapes both novices and experts alike is that make's input language is text based, as opposed to token based, as is the case for C or even the Unix shell. Make does the very least possible to process input lines and stash them away in memory.
As an example of this, consider the following assignment:
OBJ = main.o parse.o |
SRC = main.c parse.c OBJ = $(SRC:.c=.o) |
If this does not seem too problematic, consider the following Makefile:
SRC = $(shell echo 'Ouch!' 1>&2 ; echo *.[cy]) OBJ = \ $(patsubst %.c,%.o,$(filter %.c,$(SRC))) \ $(patsubst %.y,%.o,$(filter %.y,$(SRC))) test: $(OBJ) $(CC) -o $@ $(OBJ) |
If this shell command does anything complex or time consuming (and it usually does) it will take four times longer than you thought.
But it is worth looking at the other portions of that OBJ macro. Each time it is named, a huge amount of processing is performed:
Notice how many times those strings are disassembled and re-assembled. Notice how many ways that happens. This is slow. The example here names just two files but consider how inefficient this would be for 1000 files. Doing it four times becomes decidedly inefficient.
If you are using a dumb make that has no substitutions and no built-in functions, this cannot bite you. But a modern make has lots of built-in functions and can even invoke shell commands on-the-fly. The semantics of make's text manipulation is such that string manipulation in make is very CPU intensive, compared to performing the same string manipulations in C or AWK.
SRC := $(shell echo 'Ouch!' 1>&2 ; echo *.[cy]) OBJ := \ $(patsubst %.c,%.o,$(filter %.c,$(SRC))) \ $(patsubst %.y,%.o,$(filter %.y,$(SRC))) test: $(OBJ) $(CC) -o $@ $(OBJ) |
As a rule of thumb: always use immediate evaluation assignment unless you knowingly want deferred evaluation.
As an example of this, it is first necessary to describe a useful feature of GNU Make: once a Makefile has been read in, if any of its included files were out-of-date (or do not yet exist), they are re-built, and then make starts again, which has the result that make is now working with up-to-date include files. This feature can be exploited to obtain automatic include file dependency tracking for C sources. The obvious way to implement it, however, has a subtle flaw.
SRC := $(wildcard *.c) OBJ := $(SRC:.c=.o) test: $(OBJ) $(CC) -o $@ $(OBJ) include dependencies dependencies: $(SRC) depend.sh $(CFLAGS) $(SRC) > $@ |
file.o: file.c include.h ...The most simple implementation of this is to use GCC, but you will need to edit the output if you want to avoid dependencies on system include files:
#!/bin/sh gcc -M -MG $* | sed 's@ /[^ ]*@@g' |
A classic build-too-little problem, caused by giving make inadequate information, and thus causing it to build an inadequate DAG and reach the wrong conclusion.
The traditional solution is to build too much:
SRC := $(wildcard *.c) OBJ := $(SRC:.c=.o) test: $(OBJ) $(CC) -o $@ $(OBJ) include dependencies .PHONY: dependencies dependencies: $(SRC) depend.sh $(CFLAGS) $(SRC) > $@ |
There is a second problem, and that is that if any one of the C files changes, all of the C files will be re-scanned for include dependencies. This is as inefficient as having a Makefile which reads
prog: $(SRC) $(CC) -o $@ $(SRC) |
SRC := $(wildcard *.c) OBJ := $(SRC:.c=.o) test: $(OBJ) $(CC) -o $@ $(OBJ) include $(OBJ:.o=.d) %.d: %.c depend.sh $(CFLAGS) $< > $@ |
This has one more thing to fix: just as the object (.o) files depend on the source files and the include files, so do the dependency (.d) files. This means tinkering with the depend.sh script once more:
#!/bin/sh gcc -M -MG $* | sed -e 's@ /[^ ]*@@g' -e 's@^\(.*\)\.o:@\1.d \1.o:@' |
This method of determining include file dependencies results in the Makefile including more files than the original method, but opening files is less expensive than rebuilding all of the dependencies every time. Typically a developer will edit one or two files before re-building; this method will rebuild the exact dependency file affected (or more than one, if you edited an include file). On balance, this will use less CPU, and less time.
In the case of a build where nothing needs to be done, make will actually do nothing, and would work this out very quickly.
It is possible to see the whole-project make proposed here as impractical, because it does not match the evolved methods of your development process.
The whole-project make proposed here does have an effect on development methods: it can give you cleaner and simpler build environments for your developers. By using make's VPATH feature, it is possible to copy only those files you need to edit into your private work area, often called a sand-box.
The simplest explanation of what VPATH does is to make an analogy with the include file search path specified using -Ipath options to the C compiler. This set of options describes where to look for files, just as VPATH tells make where to look for files.
By using VPATH, it is possible to ``stack'' the sand-box on top of the project master source, so that files in the sand-box take precedence, but it is the union of all the files which make uses to perform the build.
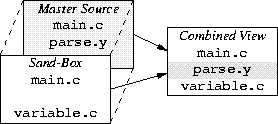
In this environment, the sand-box has the same tree structure as the project master source. This allows developers to safely change things across separate modules, e.g. if they are changing a module interface. It also allows the sand-box to be physically separate - perhaps on a different disk, or under their home directory. It also allows the project master source to be read-only, if you have (or would like) a rigorous check-in procedure.
Note: in addition to adding a VPATH line to your development Makefile, you will also need to add -I options to the CFLAGS macro, so that the C compiler uses the same path as make does. This is simply done with a 3-line Makefile in your work area - set a macro, set the VPATH, and then include the Makefile from the project master source.
Once GNU make finds a target file through VPATH/vpath it changes the target path to the VPATH/vpath name immediately, causing all dependencies of the target to be searched for in the VPATH directory to the exclusion of local files which might be newer.See the actual README file for a longer explanation.
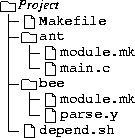
The Makefile looks like this:
MODULES := ant bee # look for include files in # each of the modules CFLAGS += $(patsubst %,-I%,$(MODULES)) # extra libraries if required LIBS := # each module will add to this SRC := # include the description for # each module include $(patsubst %,%/module.mk,$(MODULES)) # determine the object files OBJ := \ $(patsubst %.c,%.o,$(filter %.c,$(SRC))) \ $(patsubst %.y,%.o,$(filter %.y,$(SRC))) # link the program prog: $(OBJ) $(CC) -o $@ $(OBJ) $(LIBS) # include the C include # dependencies include $(OBJ:.o=.d) # calculate C include # dependencies %.d: %.c depend.sh $(CFLAGS) $< > $@ |
SRC += ant/main.c |
SRC += bee/parse.y LIBS += -ly %.c %.h: %.y $(YACC) -d %.y mv y.tab.c %.c mv y.tab.h %.h |
Notice that the built-in rules are used for the C files, but we need special yacc processing to get the generated .h file.
The equivalent DAG of the Makefile after all of the includes looks like this:
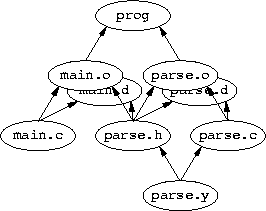
The vertexes and edges for the include file dependency files are also present as these are important for make to function correctly.
The author only started thinking about the ideas presented in this paper when faced with a number of ugly build problems on utterly different projects, but with common symptoms. By stepping back from the individual projects, and closely examining the thing they had in common, make, it became possible to see the larger pattern. Most of us are too caught up in the minutiae of just getting the rotten build to work that we don't have time to spare for the big picture. Especially when the item in question ``obviously'' works, and has done so continuously for the last 20 years.
It is interesting that the problems of recursive make are rarely mentioned in the very books Unix programmers rely on for accurate, practical advice.
It is hardly surprising that the original paper did not discuss recursive make, Unix projects at the time usually did fit into a single directory.
It may be this which set the ``one Makefile in every directory'' concept so firmly in the collective Unix development mind-set.
``This technique is useful when you want to separate makefiles for various subsystems that compose a larger system.''
No mention is made of the problems you may encounter.
``The cleanest way to build is to put a separate description file in each directory, and tie them together through a master description file that invokes make recursively. While cumbersome, the technique is easier to maintain than a single, enormous file that covers multiple directories.'' (pp. 65)This is despite the book's advice only two paragraphs earlier that
``make is happiest when you keep all your files in a single directory.'' (pp. 64)Yet the book fails to discuss the contradiction in these two statements, and goes on to describe one of the traditional ways of treating the symptoms of incomplete DAGs caused by recursive make.
The book may give us a clue as to why recursive make has been used in this way for so many years. Notice how the above quotes confuse the concept of a directory with the concept of a Makefile.
This paper suggests a simple change to the mind-set: directory trees, however deep, are places to store files; Makefiles are places to describe the relationships between those files, however many.
``If make doesn't do what you expect it to, it's a good chance the makefile is wrong.'' (p. 10)Which is a pithy summary of the thesis of this paper.
This requires a shift in thinking: directory trees are simply a place to hold files, Makefiles are a place to remember relationships between files. Do not confuse the two because it is as important to accurately represent the relationships between files in different directories as it is to represent the relationships between files in the same directory. This has the implication that there should be exactly one Makefile for a project, but the magnitude of the description can be managed by using a make include file in each directory to describe the subset of the project files in that directory.
This paper has shown how a project build and a development build can be equally brief for a whole-project make. Given this parity of time, the gains provided by accurate dependencies mean that this process will, in fact, be faster than the recursive make case, and more accurate.
Modules shared between your projects may fall into a similar category: if they change, you will deliberately re-build to include their changes, or quietly include their changes whenever the next build may happen. In either case, you do not explicitly state the dependencies, and whole-project make does not apply.
How to structure dependencies in a strong re-use environment thus becomes an exercize in risk management. What is the danger that omitting chunks of the DAG will harm your projects? How vital is it to rebuild if a module changes? What are the consequences of not rebuilding immediately? How can you tell when a rebuild is necessary if the dependencies are not explicitly stated? What are the consequences of forgetting to rebuild?
The focus of this paper is that you will get more accurate builds of your project if you use whole-project make rather than recursive make.
The disadvantages of using whole-project make over recursive make are often un-measured. How much time is spent figuring out why make did something unexpected? How much time is spent figuring out that make did something unexpected? How much time is spent tinkering with the build process? These activities are often though of as ``normal'' development overheads.
Building your project is a fundamental activity, if it is performing poorly so is development, debugging and testing. Building your project needs to be so simple the newest recruit can do it immediately with only a single page of instructions. Building your project needs to be so simple that it rarely needs any development effort at all. Is your build process this simple?
| [1] | Stuart I. Feldman, ``Make - A Program for Maintaining Computer Programs,'' Computing Science Technical Report 57, Bell Laboratories (Aug 1978). |
| [2] | Richard M. Stallman and Roland McGrath, GNU Make: A Program for Directing Recompilation, Free Software Foundation, Inc., Cambridge, Massachusetts, USA (Jul 1993). |
| [3] | Steve Talbott, Managing Projects with Make, 2nd Ed., Nutshell, O'Reilly & Associates, Inc., Newton, MA, USA (1991). ISBN: 0-937175-18-8. |
| [4] | Adam de Boor PMake - A Tutorial, University of California, Berkeley, Beley, CA, USA (Jul 1988). |